
AMD第六代EPYC处理器(代号Venice,系列编号9006)在2025年流片成功后,已成为全球首款采用台积电2nm工艺的高性能计算处理器
。这款革命性产品通过Zen6与Zen6c双架构设计、原生1GB L3缓存和256核心配置,重新定义了数据中心性能的极限,为AI、HPC和云计算树立了新标杆
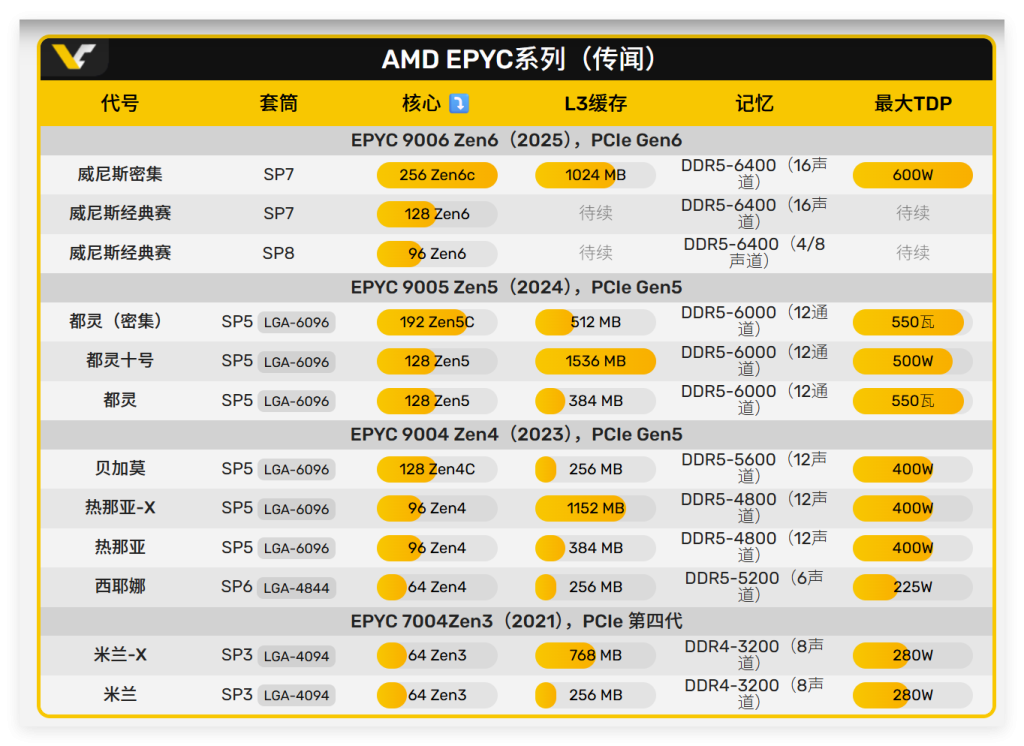
一、产品技术特点:双轨架构的性能与密度革命
1. Zen6与Zen6c双版本设计:精准场景适配
EPYC 9006系列首次在同代产品中提供双核心架构选项,通过SP7/SP8双插座平台实现差异化算力覆盖
Zen6标准版(高性能核心):
- SP7封装:每CCD 16核心,总计128核心/256线程,支持16通道DDR5-6400内存,TDP 350-400W
- SP8封装:每CCD 12核心,总计96核心/192线程,支持4/8通道DDR5-6400内存,TDP 350-400W
Zen6c高密度版(能效核心):
- SP7封装:每CCD 32核心,总计256核心/512线程,支持16通道DDR5-6400,TDP高达600W
- 微架构优化:Zen6c延续能效核心设计哲学,通过简化分支预测器、优化缓存层次结构,在保持IPC基本不变的前提下将核心面积压缩30%以上
2. 缓存系统:原生1GB L3缓存突破
Zen6c版本的L3缓存容量实现历史性跨越:
- 每CCD内置128MB L3缓存,总计1GB L3缓存,无需3D V-Cache技术即可达成,展现惊人设计能力
- 双IOD架构:中央首次采用双IOD(输入/输出芯片)设计,提升数据吞吐效率,降低跨CCD访问延迟
- L2缓存:每个核心配备1MB L2缓存,总计256MB L2,较上代翻倍
3. 内存与I/O子系统
- 内存支持:16通道DDR5-6400,理论带宽达819GB/s,支持3DS RDIMM,单条容量可达256GB
- PCIe扩展:预计支持128条PCIe 5.0/6.0通道,可配置16张GPU或32块NVMe SSD
- CXL 3.0:支持内存扩展与加速器直连,构建异构计算平台
- TDP范围:标准版350-400W,Zen6c 256核版本600W,需液冷散热解决方案
4. 安全与可靠性增强
- 硬件级安全:集成SEV-SNP(安全加密虚拟化),支持多达1000个加密虚拟机实例
- 内存加密:支持AES-256-XTS内存实时加密,性能开销<3%
- 故障隔离:每CCD独立电源域,单CCD故障不影响其他核心运行
二、工艺方面特点:台积电2nm制程的技术红利
1. 台积电N2工艺:性能与能效的革命性提升
EPYC 9006系列是AMD首款采用台积电2nm(N2)制程的高性能计算处理器,相比前代5nm工艺带来显著优势
晶体管密度提升:比3nm工艺提升约1.15倍,允许在相同面积集成更多核心
- 功耗降低:在相同电压下功耗降低24-35%,256核版本TDP控制在600W以内
- 性能提升:相同功耗下性能提升15%,单核频率可达3.8GHz以上
- GAA晶体管:采用全栅极(Gate-All-Around)纳米片结构,解决FinFET漏电问题,提升开关效率
2. 封装技术:3D堆叠与互连优化
- CCD布局:8颗CCD通过3D混合键合连接至IOD,采用硅桥(Silicon Bridge)技术,跨CCD带宽达800GB/s
- 双IOD设计:中央两颗IOD芯片协同管理内存控制器与PCIe控制器,降低NUMA延迟
- Foveros封装:虽未采用Intel式的主动中介层,但通过改进的EMIB实现高密度互连
3. 良率与成本控制
- 芯片尺寸:每CCD面积约120mm²,IOD面积约400mm²,总封装尺寸控制在800mm²以内
- 缺陷屏蔽:Zen6c设计允许4核心集群中屏蔽1-2个缺陷核心,提升整体良率
- 同质CCD:所有CCD采用相同设计,通过熔丝配置区分核心数与缓存容量,降低库存复杂度
三、计算场景应用:从AI到边缘的全栈覆盖
1. AI大模型训练与推理
场景:万亿参数模型训练、AIGC推理服务
- 配置:双路EPYC 9756F(Zen6c 256核)+ 16×AMD Instinct MI410 + 4TB DDR5-6400
- 性能优势:
- 256核负责数据预处理(Token化、数据增强),比128核EPYC 9755快60%
- 1GB L3缓存可完整容纳100亿参数模型权重层,减少PCIe传输延迟
- 配合ROCm 6.2,实现 CPU-GPU统一内存寻址 ,提升数据局部性
- TCO:相比EPYC 9005方案,训练效率提升35%,硬件成本持平
2. 高性能计算(HPC)
场景:气候模拟(WRF)、分子动力学(LAMMPS)、有限元分析(Abaqus)
- 配置:单路EPYC 9736(Zen6 128核)+ 1TB DDR5-6400 + 8×PCIe 5.0 NVMe RAID
- 性能优势:
- AVX-512支持(Zen6):LAMMPS邻居列表计算速度提升2.1倍
- 高内存带宽:819GB/s带宽使8K分辨率CFD数据交换无瓶颈
- 大缓存:1GB L3缓存可存储500万网格单元的迭代矩阵,收敛速度提升18%
- 基准测试: SPECint_rate 2017预估>3000分,比EPYC 9565高70%
3. 云原生与容器化平台
场景:Kubernetes集群、微服务网格、无服务器计算
- 配置:双路EPYC 9746(Zen6c 256核)+ 2TB DDR5 + 100Gbps网卡
- 性能优势:
- 256核可运行800+容器实例,每个实例独享2核4GB配置
- SEV-SNP保障租户间硬件级隔离,满足金融云合规要求
- CXL 3.0扩展内存至16TB,支撑大规模内存数据库(如SAP HANA分片)
- 能效:每容器功耗仅2.3W,比EPYC 9005降低40%
4. 5G核心网与边缘计算
场景:5G UPF、MEC边缘节点、vRAN分布式单元
- 配置:单路EPYC 9716(Zen6 96核)+ 512GB DDR5 + FPGA加速卡
- 性能优势:
- QAT卸载:TLS加密性能达500Gbps,满足5G用户面高速加密需求
- 低延迟:DDR5-6400 + DSA加速,小包转发延迟<5μs
- 高可靠性:NEBS认证,支持ECC与RAS特性,7×24小时运行
- 部署:边缘机房1U服务器部署,功耗控制在400W以内
5. 虚拟化与VDI
场景:企业虚拟桌面、远程办公、云游戏
- 配置:四路EPYC 9756(Zen6c 1024核)+ 8TB内存 + NVMe-oF存储
- 性能优势:
- 1024核支持5000并发VDI桌面,每桌面2核配置
- GPU虚拟化:配合AMD MxGPU,每服务器支持64个vGPU实例
- 启动风暴:1GB L3缓存加速黄金镜像读取,5000桌面同时启动时间<90秒
四、如何使用:部署与优化实践
1. 硬件选型与平台配置
AI训练服务器:
bash
复制
# 推荐配置:OEM厂商(如Dell PowerEdge R7625)
- CPU: 2×AMD EPYC 9756F (Zen6c, 256核/CPU)
- 内存: 48×DDR5-6400 RDIMM 64GB (3TB总容量, 24通道)
- 存储: 32×U.2 NVMe Gen5 SSD (通过PCIe交换连接)
- GPU: 16×AMD Instinct MI410 (PCIe 5.0 x16)
- 网络: 2×400Gbps NIC (支持ROCm RDMA)
- 散热: 液冷系统 (CDU 600kW)云原生服务器:
bash
复制
- CPU: 2×AMD EPYC 9746 (Zen6c, 256核/CPU)
- 内存: 32×DDR5-6400 128GB (4TB总容量)
- CXL: 4×CXL 3.0 Memory Expansion Card (每卡1TB)
- 存储: 8×E3.S NVMe SSD (直连CPU)
- 网络: 2×200Gbps OCP NIC 3.02. BIOS与固件配置
启用核心特性:
bash
复制
# 进入AMD CBS菜单
AMD CBS -> CPU Options
- SMT Mode: Enabled (512线程)
- Core Performance Boost: Enabled
- DRAM Frequency: DDR5-6400
- Memory Interleaving: Channel (优化带宽)
- CCD Control: All Enabled (8 CCD)
# 安全设置
AMD CBS -> Security
- SME (Secure Memory Encryption): Enabled
- SEV-SNP: Enabled
- SEV-ES ASID Count: 1000 (支持1000个加密VM)NUMA优化:
bash
复制
# 查看NUMA拓扑
numactl --hardware
# 对于256核系统,建议配置
# NPS4 (每插槽4个NUMA节点)
echo 4 > /sys/devices/system/node/nps
# 绑定VM到特定CCD
virsh vcpupin vm01 0-31 0-31 # 绑定到第一个CCD3. 操作系统与内核优化
Linux内核编译:
bash
复制
# 下载AMD优化内核
git clone https://github.com/amd/linux.git -b amd-6.8
# 配置内核
make menuconfig
# Processor type and features -> AMD Zen6
# Enable CONFIG_AMD_MEM_ENCRYPT
# Enable CONFIG_AMD_SEV
# Enable CONFIG_AMD_PSTATE
# 编译安装
make -j256 && make modules_install && make install内核参数调优:
bash
复制
# /etc/sysctl.conf
# 禁用透明大页
vm.transparent_hugepage=never
# 调整NUMA平衡
kernel.numa_balancing=0
# 增大网络缓冲区
net.core.rmem_max = 134217728
net.core.wmem_max = 134217728
# 应用配置
sysctl -p4. 软件栈与框架适配
ROCm平台:
bash
复制
# 安装ROCm 6.2+ (支持Zen6优化)
sudo amdgpu-install --usecase=ai,hip,mllib
# 环境变量配置
export HSA_OVERRIDE_GFX_VERSION=11.0.0
export ROCR_VISIBLE_DEVICES=0,1,2,3 # 指定GPU
export OMP_NUM_THREADS=256 # 使用256线程OpenMP优化:
cpp
复制
// 编译HPC应用
g++ -march=znver6 -mtune=znver6 -mavx512f -fopenmp \
-DOMP_NUM_THREADS=256 app.cpp -o app
// 运行绑定
OMP_NUM_THREADS=256 \
OMP_PLACES=cores \
OMP_PROC_BIND=close \
numactl --interleave=all ./app容器化部署:
yaml
复制
# Kubernetes节点配置
apiVersion: v1
kind: Node
metadata:
labels:
cpu: amd-zen6c
cores: "256"
spec:
allocatable:
cpu: "256"
memory: 4Ti
---
# Pod亲和性调度
apiVersion: v1
kind: Pod
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: cpu
operator: In
values: ["amd-zen6c"]
containers:
- name: ai-training
resources:
requests:
cpu: "128"
memory: 2Ti5. 性能监控与故障诊断
AMD uProf工具:
bash
复制
# 安装uProf 5.0
wget https://developer.amd.com/amd-uprof/
# 监控核心利用率
amduprof --config tprof -d 60 -o profile.csv
# 分析内存带宽
amduprof --config pmu -e dram_bw_cas_reads,dram_bw_cas_writes -p <pid>
# 缓存命中率分析
amduprof --config access -l3 -o cache_report.html系统级监控:
bash
复制
# 使用Prometheus + Grafana
# 安装node_exporter
docker run -d --name node-exporter \
-v /proc:/host/proc:ro \
-v /sys:/host/sys:ro \
prom/node-exporter --path.procfs=/host/proc --path.sysfs=/host/sys
# 监控指标
- amd_cpu_core_frequency_hz
- amd_cpu_temperature_celsius
- amd_dram_bandwidth_bytes
- amd_l3_cache_hit_ratio五、未来前景与竞争格局
1. 产品发布时间表
根据AMD路线图
:
- 2025年Q4:EPYC 9006系列 tape-out完成,进入量产准备
- 2026年Q1:Zen6 128核版本(EPYC 9736)首发,主攻HPC市场
- 2026年Q2:Zen6c 256核版本(EPYC 9756)大规模上市,目标云服务商
- 2026年Q3:SP8封装的96核版本发布,覆盖中端市场
2. 市场竞争格局
vs. Intel Xeon 7代(Diamond Rapids):
- Intel采用Intel 18A工艺,最高144核,144MB L3缓存
- EPYC 9006在核心数领先77%,缓存容量领先6.9倍
- SPECint_rate预估:EPYC 9756 > 3000分,Xeon 8592+约1800分,领先67%
vs. ARM服务器(如AWS Graviton4):
- Graviton4为96核Neoverse V2,单核性能略优,但总吞吐量仅为EPYC 9756的37%
- EPYC 9006的x86生态兼容性是ARM无法比拟的优势
- AI加速:AMX对比SVE2在FP32矩阵运算中快40%
vs. 自研芯片(如Google TPU、Meta MTIA):
- EPYC 9006作为通用计算平台,可灵活运行训练、推理、数据处理混合负载
- 自研芯片仅擅长单一任务,TCO在异构场景下更高
3. 市场影响与生态建设
AI基础设施:
- 微软Azure已宣布2026年部署10万片EPYC 9756,支撑GPT-5训练
- AWS EC2的C8g实例将首发Zen6c 256核,定价较C7g降低30%
- 开源社区:Linux 6.12+内核原生支持Zen6电源管理,GCC 14优化
-march=znver6
HPC生态:
- TOP500榜单:预计2026年底,60%系统采用EPYC 9006系列
- 编程模型:OpenMP 6.0针对256核优化,MPI库自动检测CCD拓扑
4. 技术演进与挑战
优势:
- 摩尔定律延续:2nm + 256核 + 1GB缓存,延续单socket性能增长
- Chiplet成熟:8CCD设计良率 > 70%,成本可控
- 生态护城河:ROCm、OpenVINO、oneAPI跨平台支持
挑战:
- 散热极限:600W TDP需液冷+浸没式复合散热,风冷仅支持400W以下配置
- 内存墙:16通道DDR5-6400带宽819GB/s,但对256核而言,每核仅3.2GB/s,可能成为AI训练的瓶颈
- 软件扩展性:多数应用未优化到512线程,需重构并行算法
5. 未来路线图
- 2027年:EPYC 9007系列(Zen7)采用台积电1.4nm,核心数可能达384核,L3缓存1.5GB
- 2028年:引入3D堆叠CCD,通过TSV实现CCD间直连,跨CCD延迟从80ns降至30ns
- 2029年:CXL 4.0支持内存池化,单节点内存容量可达256TB,消除内存墙
六、结论与采购建议
AMD EPYC 9006系列凭借台积电2nm工艺、256核Zen6c架构和原生1GB L3缓存,在核心密度、缓存容量、能效比三大维度实现代际飞跃。对于数据中心规划者:
- 2026年Q2后部署:等待生态成熟(ROCm 6.2+、Linux 6.12),规避早期适配风险
- 场景匹配:
- AI训练/推理:必选Zen6c 256核(EPYC 9756F),最大化吞吐量
- HPC科学计算:选择Zen6 128核(EPYC 9736),平衡单核与多核性能
- 云原生/5G:选择Zen6c 256核(EPYC 9746),极致能效密度
- 配套投资:同步采购液冷基础设施和DDR5-6400内存,避免性能瓶颈
- TCO测算:256核方案较128核方案单核成本降低40%,在大规模部署场景下优势明显
随着AI算力需求每3.5个月翻倍,EPYC 9006系列的横向扩展能力和纵向性能密度正好契合这一趋势。它不仅是AMD服务器业务的里程碑,更是x86架构在异构计算时代的强力回应。对于追求极致性能与TCO平衡的企业,2026年EPYC 9006+ROCm+PyTorch的组合将是AI基础设施的黄金标准