过去做企业级IT,如今搞企业级AI,都有点像跑船打渔,船越大就越不能只图快,更得求稳,否则船一翻,载得渔获越多损失就越重。确实是风浪越大鱼越贵,前提是你得平安返港。
再具象点说,你可能听过这样的数据:超40%的大中型企业每小时停机成本超过100万美元,甚至超过500万美元,这不是耸人听闻,是来自实际统计。在“算力即财富”的AI时代,服务器宕机带来的损失,比直接烧钱来得还快!而且这种情况出现的可能性还挺高,毕竟AI集群正加速向万卡级规模突破,系统越复杂、计算密度越高,就越可能出现更多的静默数据错误(SDE)及发生在内存与PCIe等组件中的故障。
别等问题发生时我们才警觉:不能只将目光聚焦在GPU或各种AI加速器的算力能否充分发挥上。没有一个稳定可靠的运行环境,这种发挥就不能持久,而不持久比不充分更亏本儿。
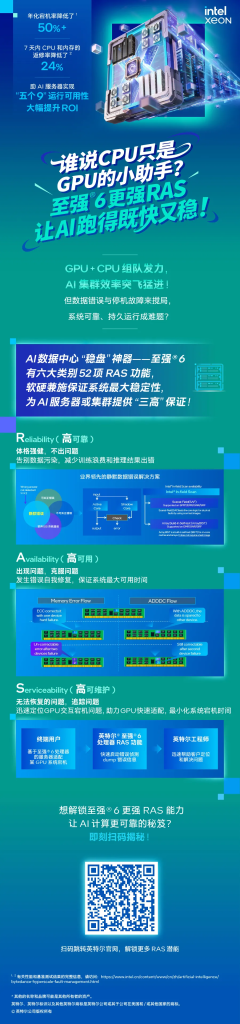
谁能从根本上解决这个问题?指望加速器芯片不现实,毕竟它们的任务是计算,需要依赖主控(或机头)系统才能进行工作,你要依赖的,恰恰是一直在AI服务器或集群中被视为“配角“的CPU。如果你选择至强® 6 处理器作为机头或主控,它的“三高”能力(高可靠性、高可用性、高可维护性,RAS)就能接过保障整体系统稳定运行的重任,为GPU创造一个“心无旁骛”、“全力输出”的环境,实现整个系统1+1>2的效能倍增。
或许你会说,各家企业级CPU都有RAS特性或功能啊,为啥如此强调至强® 6?这是因为它有一些独具且强化的功能,能帮你的AI平台与应用更好地避坑:
告别“数据污染”,
为GPU扫清“静默错误雷区”
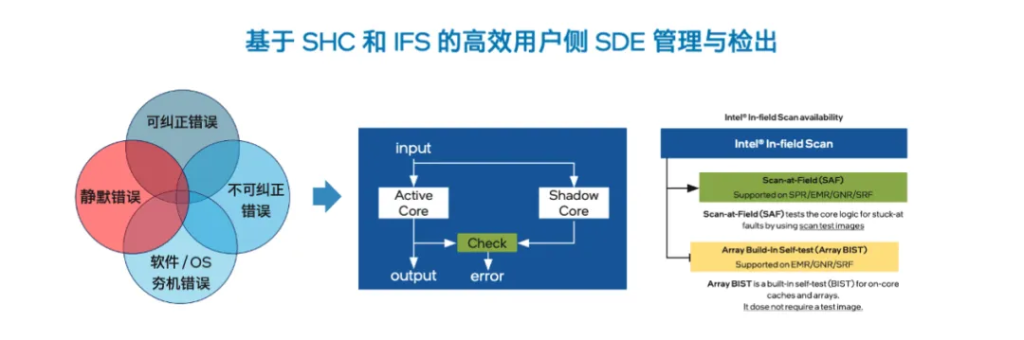
在动辄千卡万卡的AI集群中,一些微小的静默数据错误就像潜伏的“地雷”,平时难以察觉,一旦“引爆”就可能污染训练结果、干扰模型收敛,以及导致错误的推理结果。
担当机头或主控系统核心的至强® 6,能主动扮演“排雷兵”的角色。它的绝技是利用硬件故障压测与复检工具套件 (SHC & DCDiag),锁步模式 (Lock Step Mode) 和故障扫描巡检(In-Field-Scan)等SDE检出功能,对GPU前行的“道路“进行细致排查,提前揪出并排除这些“隐形错误”。这确保了机头或主控CPU交付给GPU的计算任务是更为纯净或可靠的,能让GPU的每一次运算都建立在更坚实可信的基础之上。
终结“频繁宕机”:
用更强可用性给GPU稳定工作上保险
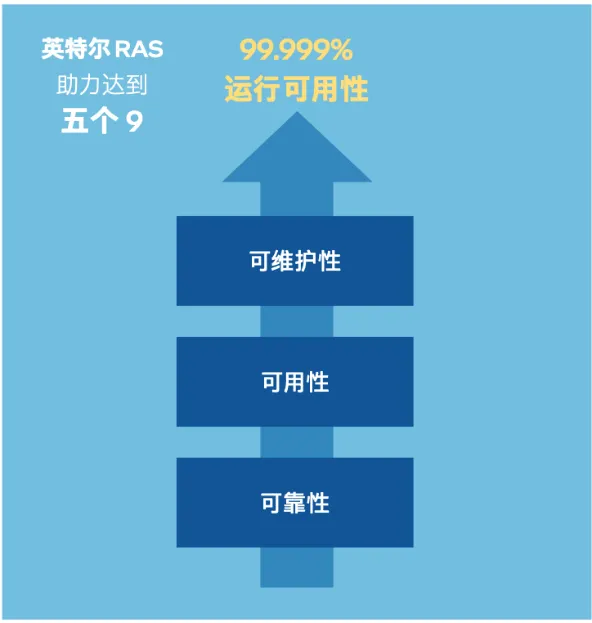
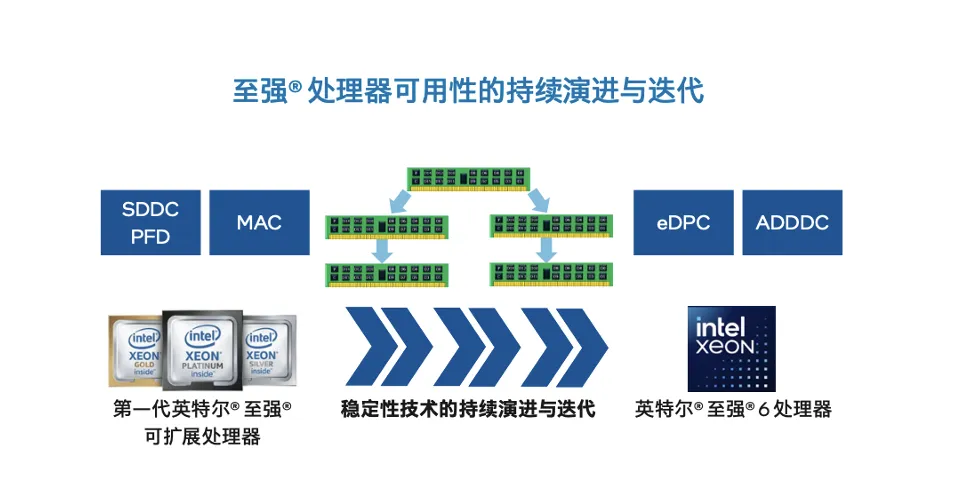
可用性是AI集群“持久连续运行”的关键,至强® 6在这方面承袭了英特尔在至强产品线上长达6代的技术迭代,积累了不少绝活儿,如:
- 内存纠错与排障:通过SDDC、ADDDC等技术,能100%纠正单颗粒内存错误,并自适应修正多颗粒错误,为GPU提供稳定的数据通路。
- 服务容错:MCA Recovery机制确保服务器在遇到非致命错误时可以“带病运行”,避免GPU工作流无故中断,到至强® 6这一代,MCA Recovery还实现了更多恢复手段。
- PCIe稳健器:eDPC功能保障了GPU与系统之间高速数据链路的稳定,这对于依赖海量数据交换的AI任务至关重要。
“首席技术支持” 为AI集群
构建分钟级故障诊断与恢复体系
作为AI集群7 x 24小时待命的“首席技术支持”,至强® 6 处理器配备RAS Offload与增强的内存故障EDAC driver,用来丰富故障上报信息,同时规避业务中断影响与性能抖动。
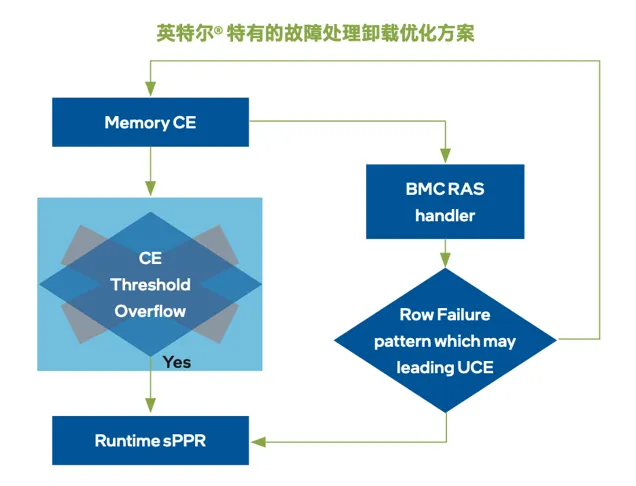
ACD、ASD等高级诊断工具,能将故障诊断的SLA(服务等级协议)从“周”级压缩到“分钟”级。

更重要的是,作为AI集群“压舱石”,至强® 6能通过上述工具链快速适配不同品牌GPU或AI加速器,辅助诊断、迅速定位并协助解决它们的故障,最大程度缩短整个系统的中断时间,让它们能“物尽其用”。
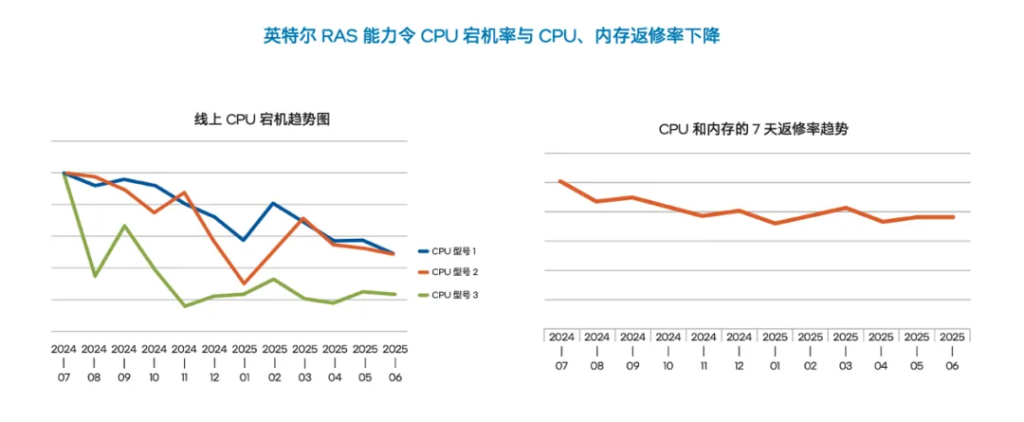
至强® 6这“三高“能力叠加起来,就构成了目前AI服务器/集群机头或主控领域独一份的控场稳盘能力。有国内某头部AI大厂的实践证明,通过综合应用至强这些RAS能力,CPU造成的宕机率已被降低了50%,二次返修率也显著下降,让其服务器的投资有了更优的回报。
最后说个让你意想不到的数字——至强® 6平台,目前在RAS具体特性或功能上,已集成了多达六大类52项细分功能,这些功能可能远不如表面“可见”的CPU核心数、主频、内存带宽、互连通道等与性能密切相关的规格那样醒目或振奋人心,但一旦遇到麻烦,你就会觉得它们还是多多易善、越强越好。这情形就像大船上的水密隔舱,平时用不上看不到以为是累赘,等撞上礁石,它们带给你的,是带伤也可继续工作并能平安返港回家的从容。